
Machine Translation Toy Dataset → Google Translate
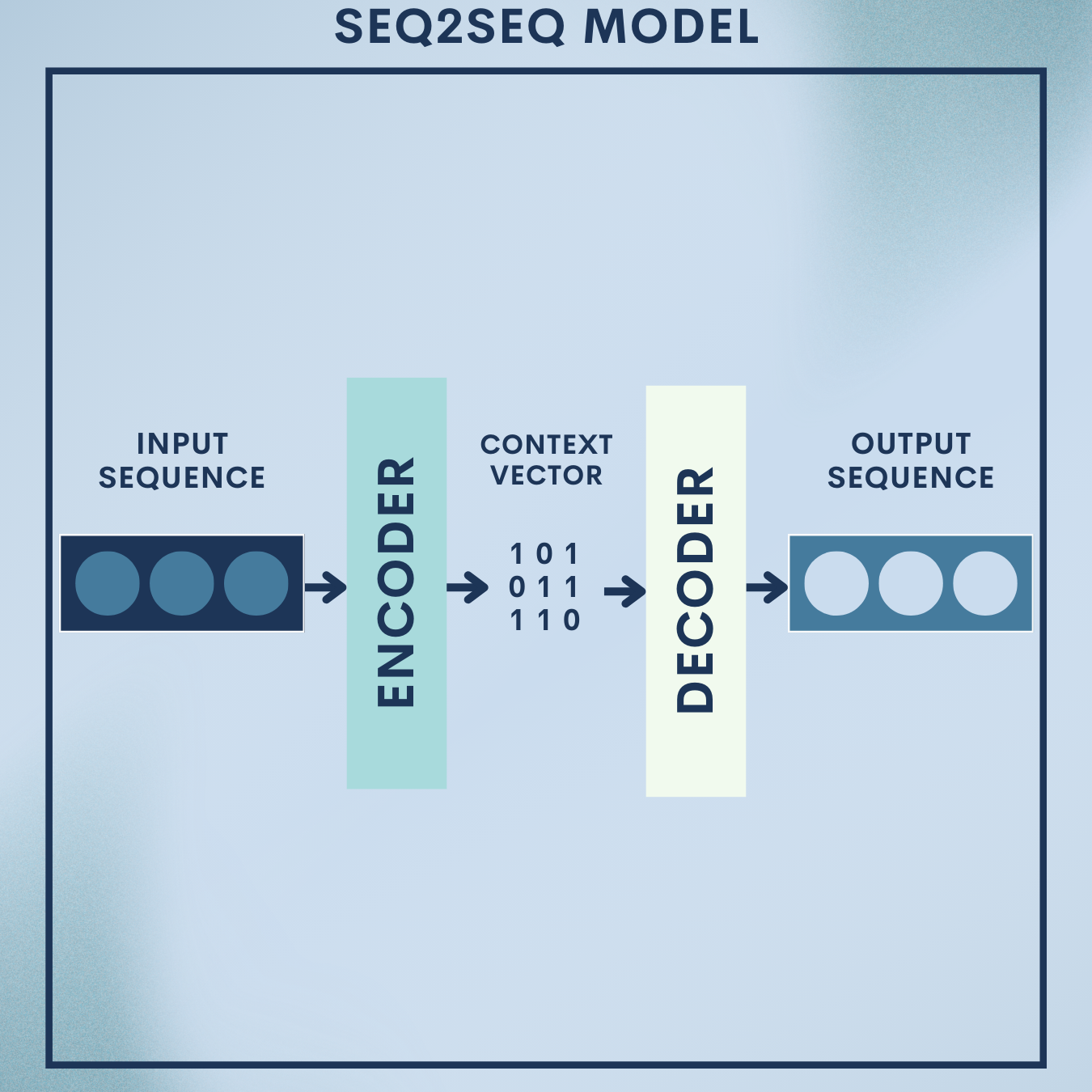
Why Seq2Seq Models?
Machine translation is the canonical “sequence-in, sequence-out” problem: given a source sentence (e.g., English), output a target sentence (e.g., French). Sequence-to-Sequence (Seq2Seq) models tackle this end-to-end, learning how to compress an input sequence into a representation and then generate the output sequence token by token.
What you’ll build here:
- Toy problem: an English→French translator trained from scratch on a tiny parallel corpus using an encoder–decoder with attention (PyTorch).
- Real-world app: a production-style workflow using Hugging Face to fine-tune a pre-trained MarianMT model for domain-adapted translation, plus evaluation with sacreBLEU—the same style of pipeline that systems like Google Translate popularized (though modern systems use Transformers at scale). Key breakthroughs that made this possible include the original LSTM encoder–decoder for Seq2Seq, additive/dot-product attention for alignment, and later, the Transformer.
Theory Deep Dive
1. Problem Formulation
Given a source sequence 


At inference, we predict 
2. Encoder–decoder (RNN/LSTM/GRU)
Encoder: reads 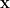

where 


Decoder: generates each 
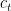
![s_t = g(s_{t-1}, E_y(y_{t-1}), c_t), \quad p(y_t \mid \cdot)=\mathrm{softmax}(W_o[s_t; c_t]).](https://s0.wp.com/latex.php?latex=s_t+%3D+g%28s_%7Bt-1%7D%2C+E_y%28y_%7Bt-1%7D%29%2C+c_t%29%2C+%5Cquad+p%28y_t+%5Cmid+%5Ccdot%29%3D%5Cmathrm%7Bsoftmax%7D%28W_o%5Bs_t%3B+c_t%5D%29.&bg=ffffff&fg=000&s=0&c=20201002)
The original Seq2Seq compressed the entire source into a single vector (the final encoder state)—effective but a bottleneck for long sentences. Attention solves this.
3. Attention (alignment)
We compute attention energies 



- Score (additive/Bahdanau):
- Or dot/Luong:
(or simple dot without
)
- Weights: $latex \alpha_{t,s} = \mathrm{softmax}s(e{t,s})$
- Context:


Attention lets the decoder “look back” at the most relevant source positions for each generated token, enabling better long-range dependencies and interpretability via alignment heatmaps.
4. Training objective & teacher forcing
We minimize token-level cross-entropy:

Teacher forcing feeds the gold 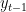
5. Decoding: greedy vs. beam search, length norm, coverage
Greedy: at each step choose 
Beam search: keep top-
Practical tricks: length normalization (avoid short outputs) and coverage penalties (discourage skipping source words)—popularized by GNMT.
6. Subword tokenization (WordPiece/BPE)
Rare words explode the vocabulary. Subword units (e.g., WordPiece, BPE) strike a balance between characters and words, improving OOV handling—a critical feature in production systems like GNMT.
7. Evaluation: BLEU
BLEU compares $n$-grams between candidate and reference translations with a brevity penalty:
$latex \mathrm{BLEU} = \mathrm{BP} \cdot \exp\left(\sum_{n=1}^{N} w_n \log p_n\right), \quad \mathrm{BP} =
\begin{cases}
1 & \text{if } c>r \
e^{1-r/c} & \text{if } c \le r
\end{cases}$
Here 


8. Where Transformers fit
Transformers replace recurrence with self-attention and encoder–decoder attention, achieving superior MT speed/quality and becoming the modern default. We still cover RNN-based Seq2Seq here because it teaches core alignment/decoding ideas that transfer to Transformers.
Toy Problem – English→French on a tiny parallel corpus (PyTorch)
Goal: implement a compact encoder–decoder with Luong dot-product attention, train on a tiny custom dataset, then translate new sentences.
Data Snapshot
| English | French |
|---|---|
| i am cold | je suis froid |
| i am hungry | j’ai faim |
| he is tired | il est fatigué |
| she is happy | elle est heureuse |
| we are students | nous sommes étudiants |
| they are doctors | ils sont médecins |
| where is the station ? | où est la gare ? |
| good morning | bonjour |
| thank you | merci |
| see you later | à plus tard |
Notes: We’ll lowercase, add start/end tokens
<sos>,<eos>, and build vocabularies on this mini dataset.
Step 1: Setup & pairs
Creates a tiny parallel corpus and basic imports.
# Toy Seq2Seq with attention (PyTorch)
import math, random, time
from collections import Counter
import torch, torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
pairs = [
("i am cold", "je suis froid"),
("i am hungry", "j'ai faim"),
("he is tired", "il est fatigué"),
("she is happy", "elle est heureuse"),
("we are students", "nous sommes étudiants"),
("they are doctors", "ils sont médecins"),
("where is the station ?", "où est la gare ?"),
("good morning", "bonjour"),
("thank you", "merci"),
("see you later", "à plus tard"),
]
Step 2: Tokenization & vocab
Builds source/target vocab; converts text to token ids, adding <sos>/<eos> for decoder.
SOS, EOS, PAD, UNK = "<sos>", "<eos>", "<pad>", "<unk>"
def tokenize(s):
return s.strip().lower().split()
def build_vocab(texts, min_freq=1):
cnt = Counter(tok for s in texts for tok in tokenize(s))
itos = [PAD, SOS, EOS, UNK] + [w for w, c in cnt.items() if c >= min_freq and w not in {PAD,SOS,EOS,UNK}]
stoi = {w:i for i,w in enumerate(itos)}
return stoi, itos
src_texts = [s for s,_ in pairs]
tgt_texts = [t for _,t in pairs]
src_stoi, src_itos = build_vocab(src_texts)
tgt_stoi, tgt_itos = build_vocab(tgt_texts)
def numericalize(s, stoi, add_sos_eos=False):
toks = tokenize(s)
ids = [stoi.get(t, stoi[UNK]) for t in toks]
if add_sos_eos:
ids = [stoi[SOS]] + ids + [stoi[EOS]]
return torch.tensor(ids, dtype=torch.long)
Step 3: Dataset & batching
Pads variable-length sequences into tensors suitable for minibatching.
def make_batch(pairs):
src_list, tgt_in_list, tgt_out_list = [], [], []
for s, t in pairs:
src = numericalize(s, src_stoi, add_sos_eos=False)
tgt = numericalize(t, tgt_stoi, add_sos_eos=True)
# teacher forcing: decoder gets <sos>...<last-1> as input, predicts next tokens
tgt_in = tgt[:-1]
tgt_out = tgt[1:]
src_list.append(src)
tgt_in_list.append(tgt_in)
tgt_out_list.append(tgt_out)
src_pad = pad_sequence(src_list, batch_first=True, padding_value=src_stoi[PAD])
tgt_in_pad = pad_sequence(tgt_in_list, batch_first=True, padding_value=tgt_stoi[PAD])
tgt_out_pad = pad_sequence(tgt_out_list, batch_first=True, padding_value=tgt_stoi[PAD])
return src_pad.to(device), tgt_in_pad.to(device), tgt_out_pad.to(device)
train_src, train_tin, train_tout = make_batch(pairs)
Step 4: Encoder (GRU)
Encodes the source into hidden states 
class Encoder(nn.Module):
def __init__(self, vocab_size, emb_dim=128, hid_dim=256):
super().__init__()
self.emb = nn.Embedding(vocab_size, emb_dim, padding_idx=src_stoi[PAD])
self.gru = nn.GRU(emb_dim, hid_dim, batch_first=True, bidirectional=False)
def forward(self, src, src_mask=None):
# src: [B, S]
x = self.emb(src)
H, h_last = self.gru(x) # H: [B, S, H], h_last: [1,B,H]
return H, h_last.squeeze(0) # return all states and final state
Step 5: Luong dot-product Attention
Computes attention weights over encoder states and returns the context vector
class DotAttention(nn.Module):
def __init__(self, hid_dim):
super().__init__()
self.scale = 1.0 / math.sqrt(hid_dim)
def forward(self, query, keys, values, mask=None):
# query: [B,H]; keys/values: [B,S,H]
scores = torch.einsum("bh,bsh->bs", query, keys) * self.scale # dot
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
alpha = scores.softmax(dim=-1) # [B,S]
ctx = torch.einsum("bs,bsh->bh", alpha, values)
return ctx, alpha
Step 6: Decoder with attention
Each step attends to the encoder, updates the decoder state, and predicts the next token distribution.
class Decoder(nn.Module):
def __init__(self, vocab_size, emb_dim=128, hid_dim=256):
super().__init__()
self.emb = nn.Embedding(vocab_size, emb_dim, padding_idx=tgt_stoi[PAD])
self.gru = nn.GRU(emb_dim + hid_dim, hid_dim, batch_first=True)
self.attn = DotAttention(hid_dim)
self.out = nn.Linear(hid_dim + hid_dim, vocab_size)
def forward(self, tgt_in, init_state, enc_states, src_mask=None):
# teacher-forced decoding across full time
B, T = tgt_in.size()
y = self.emb(tgt_in) # [B,T,E]
s_t = init_state # [B,H]
logits = []
for t in range(T):
ctx, _ = self.attn(s_t, enc_states, enc_states, mask=src_mask)
inp = torch.cat([y[:,t,:], ctx], dim=-1).unsqueeze(1) # [B,1,E+H]
o, s_t = self.gru(inp, s_t.unsqueeze(0))
s_t = s_t.squeeze(0)
out_t = self.out(torch.cat([o.squeeze(1), ctx], dim=-1)) # [B,V]
logits.append(out_t)
return torch.stack(logits, dim=1) # [B,T,V]
Step 7: Training loop
Optimizes cross-entropy with gradient clipping; prints quick progress.
enc = Encoder(len(src_itos)).to(device)
dec = Decoder(len(tgt_itos)).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=tgt_stoi[PAD])
opt = torch.optim.Adam(list(enc.parameters())+list(dec.parameters()), lr=3e-3)
def src_mask_from(src):
return (src != src_stoi[PAD]).long() # [B,S]
for epoch in range(400): # tiny dataset → small epochs
enc.train(); dec.train()
src, tin, tout = train_src, train_tin, train_tout
opt.zero_grad()
H, h_last = enc(src, None)
mask = src_mask_from(src)
logits = dec(tin, h_last, H, mask)
loss = criterion(logits.view(-1, logits.size(-1)), tout.reshape(-1))
loss.backward()
nn.utils.clip_grad_norm_(list(enc.parameters())+list(dec.parameters()), 1.0)
opt.step()
if (epoch+1) % 100 == 0:
print(f"epoch {epoch+1} | loss {loss.item():.3f}")
Step 8: Greedy inference
Runs encoder once, then decodes step-by-step, stopping at <eos>.
def translate(sentence, max_len=20):
enc.eval(); dec.eval()
src = numericalize(sentence, src_stoi).unsqueeze(0).to(device)
H, h_last = enc(src, None)
mask = (src != src_stoi[PAD]).long()
y = torch.tensor([[tgt_stoi[SOS]]], device=device)
s_t = h_last
outputs = []
for _ in range(max_len):
ctx, _ = dec.attn(s_t, H, H, mask)
inp = torch.cat([dec.emb(y)[:, -1, :], ctx], dim=-1).unsqueeze(1)
o, s_t = dec.gru(inp, s_t.unsqueeze(0))
s_t = s_t.squeeze(0)
logits = dec.out(torch.cat([o.squeeze(1), ctx], dim=-1))
next_id = int(logits.argmax(dim=-1))
if tgt_itos[next_id] == EOS: break
outputs.append(tgt_itos[next_id])
y = torch.cat([y, torch.tensor([[next_id]], device=device)], dim=1)
return " ".join(outputs)
print(translate("i am hungry"))
Quick Reference: Full Code
# toy_seq2seq_en_fr.py
# Compact encoder–decoder with Luong dot attention on a tiny EN→FR corpus
import math, random, time
from collections import Counter
import torch, torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
torch.manual_seed(0); random.seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# -----------------------
# Data (tiny parallel set)
# -----------------------
pairs = [
("i am cold", "je suis froid"),
("i am hungry", "j'ai faim"),
("he is tired", "il est fatigué"),
("she is happy", "elle est heureuse"),
("we are students", "nous sommes étudiants"),
("they are doctors", "ils sont médecins"),
("where is the station ?", "où est la gare ?"),
("good morning", "bonjour"),
("thank you", "merci"),
("see you later", "à plus tard"),
]
SOS, EOS, PAD, UNK = "<sos>", "<eos>", "<pad>", "<unk>"
def tokenize(s):
return s.strip().lower().split()
def build_vocab(texts, min_freq=1):
cnt = Counter(tok for s in texts for tok in tokenize(s))
itos = [PAD, SOS, EOS, UNK] + [w for w,c in cnt.items() if c>=min_freq and w not in {PAD,SOS,EOS,UNK}]
stoi = {w:i for i,w in enumerate(itos)}
return stoi, itos
src_texts = [s for s,_ in pairs]
tgt_texts = [t for _,t in pairs]
src_stoi, src_itos = build_vocab(src_texts)
tgt_stoi, tgt_itos = build_vocab(tgt_texts)
def numericalize(s, stoi, add_sos_eos=False):
ids = [stoi.get(t, stoi[UNK]) for t in tokenize(s)]
if add_sos_eos:
ids = [stoi[SOS]] + ids + [stoi[EOS]]
return torch.tensor(ids, dtype=torch.long)
def make_batch(pairs):
src_list, tgt_in_list, tgt_out_list = [], [], []
for s, t in pairs:
src = numericalize(s, src_stoi, add_sos_eos=False)
tgt = numericalize(t, tgt_stoi, add_sos_eos=True)
tgt_in, tgt_out = tgt[:-1], tgt[1:]
src_list.append(src); tgt_in_list.append(tgt_in); tgt_out_list.append(tgt_out)
src_pad = pad_sequence(src_list, batch_first=True, padding_value=src_stoi[PAD])
tin_pad = pad_sequence(tgt_in_list, batch_first=True, padding_value=tgt_stoi[PAD])
tout_pad = pad_sequence(tgt_out_list, batch_first=True, padding_value=tgt_stoi[PAD])
return src_pad.to(device), tin_pad.to(device), tout_pad.to(device)
train_src, train_tin, train_tout = make_batch(pairs)
# -----------------------
# Model: Encoder / Attn / Decoder
# -----------------------
class Encoder(nn.Module):
def __init__(self, vocab_size, emb_dim=128, hid_dim=256):
super().__init__()
self.emb = nn.Embedding(vocab_size, emb_dim, padding_idx=src_stoi[PAD])
self.gru = nn.GRU(emb_dim, hid_dim, batch_first=True)
def forward(self, src):
x = self.emb(src) # [B,S,E]
H, h_last = self.gru(x) # H: [B,S,H], h_last: [1,B,H]
return H, h_last.squeeze(0) # [B,S,H], [B,H]
class DotAttention(nn.Module):
def __init__(self, hid_dim):
super().__init__()
self.scale = 1.0 / math.sqrt(hid_dim)
def forward(self, query, keys, values, mask=None):
# query: [B,H], keys/values: [B,S,H], mask: [B,S] (1=keep, 0=pad)
scores = torch.einsum("bh,bsh->bs", query, keys) * self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
alpha = scores.softmax(dim=-1) # [B,S]
ctx = torch.einsum("bs,bsh->bh", alpha, values)
return ctx, alpha
class Decoder(nn.Module):
def __init__(self, vocab_size, emb_dim=128, hid_dim=256):
super().__init__()
self.emb = nn.Embedding(vocab_size, emb_dim, padding_idx=tgt_stoi[PAD])
self.gru = nn.GRU(emb_dim + hid_dim, hid_dim, batch_first=True)
self.attn = DotAttention(hid_dim)
self.out = nn.Linear(hid_dim + hid_dim, vocab_size)
def forward(self, tgt_in, init_state, enc_states, src_mask=None):
B, T = tgt_in.size()
y = self.emb(tgt_in) # [B,T,E]
s_t = init_state # [B,H]
logits = []
for t in range(T):
ctx, _ = self.attn(s_t, enc_states, enc_states, mask=src_mask) # [B,H]
inp = torch.cat([y[:,t,:], ctx], dim=-1).unsqueeze(1) # [B,1,E+H]
o, s_t = self.gru(inp, s_t.unsqueeze(0))
s_t = s_t.squeeze(0) # [B,H]
out_t = self.out(torch.cat([o.squeeze(1), ctx], dim=-1)) # [B,V]
logits.append(out_t)
return torch.stack(logits, dim=1) # [B,T,V]
# -----------------------
# Train
# -----------------------
enc = Encoder(len(src_itos)).to(device)
dec = Decoder(len(tgt_itos)).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=tgt_stoi[PAD])
opt = torch.optim.Adam(list(enc.parameters()) + list(dec.parameters()), lr=3e-3)
def src_mask_from(src):
return (src != src_stoi[PAD]).long()
EPOCHS = 300
for epoch in range(EPOCHS):
enc.train(); dec.train()
src, tin, tout = train_src, train_tin, train_tout
opt.zero_grad()
H, h_last = enc(src)
mask = src_mask_from(src)
logits = dec(tin, h_last, H, mask)
loss = criterion(logits.view(-1, logits.size(-1)), tout.reshape(-1))
loss.backward()
nn.utils.clip_grad_norm_(list(enc.parameters())+list(dec.parameters()), 1.0)
opt.step()
if (epoch+1) % 100 == 0:
print(f"epoch {epoch+1} | loss {loss.item():.3f}")
# -----------------------
# Inference (greedy)
# -----------------------
def translate(sentence, max_len=20):
enc.eval(); dec.eval()
src = numericalize(sentence, src_stoi).unsqueeze(0).to(device)
H, h_last = enc(src)
mask = (src != src_stoi[PAD]).long()
y = torch.tensor([[tgt_stoi[SOS]]], device=device)
s_t = h_last
outputs = []
for _ in range(max_len):
ctx, _ = dec.attn(s_t, H, H, mask)
inp = torch.cat([dec.emb(y)[:, -1, :], ctx], dim=-1).unsqueeze(1)
o, s_t = dec.gru(inp, s_t.unsqueeze(0))
s_t = s_t.squeeze(0)
logits = dec.out(torch.cat([o.squeeze(1), ctx], dim=-1))
next_id = int(logits.argmax(dim=-1))
token = tgt_itos[next_id]
if token == EOS: break
outputs.append(token)
y = torch.cat([y, torch.tensor([[next_id]], device=device)], dim=1)
return " ".join(outputs)
# Quick tests
for s in ["i am hungry", "thank you", "where is the station ?"]:
print(f"{s} -> {translate(s)}")
Real‑World Application — Fine-tune a pre-trained MarianMT model (Hugging Face)
Goal: domain-adapt a strong baseline translator (e.g., English→French) with a small parallel dataset, evaluate with sacreBLEU, and run inference. This mirrors production workflows: start from a robust pre-trained model, then fine-tune to your domain (e.g., product manuals, support emails).
Step 1: Install & imports
Grabs the standard MT stack: transformers + datasets + sacreBLEU.
# !pip install -q transformers datasets accelerate evaluate sacrebleu
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from transformers import DataCollatorForSeq2Seq, TrainingArguments, Trainer
import evaluate, numpy as np
Step 2: Load a small parallel dataset
Loads English–French sentence pairs for quick experiments.
# OPUS Books is a small parallel corpus suitable for demos
data = load_dataset("opus_books", "en-fr")
data = data["train"].train_test_split(test_size=0.1, seed=42)
train_ds, test_ds = data["train"], data["test"]
len(train_ds), len(test_ds)
Step 3: Load tokenizer & model (MarianMT)
Initializes a strong off-the-shelf translator you can fine-tune.
model_name = "Helsinki-NLP/opus-mt-en-fr"
tok = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
Step 4: Preprocess to model inputs
Tokenizes source/target and attaches labels suitable for Seq2Seq training.
src_lang, tgt_lang = "en", "fr"
max_len = 128
def preprocess(batch):
src = batch["translation"][src_lang]
tgt = batch["translation"][tgt_lang]
model_inputs = tok(src, max_length=max_len, truncation=True)
with tok.as_target_tokenizer():
labels = tok(tgt, max_length=max_len, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
train_tok = train_ds.map(preprocess, batched=True, remove_columns=train_ds.column_names)
test_tok = test_ds.map(preprocess, batched=True, remove_columns=test_ds.column_names)
Step 5: Data collator & metrics (sacreBLEU)
Uses standardized BLEU for MT evaluation.
data_collator = DataCollatorForSeq2Seq(tok, model=model)
bleu = evaluate.load("sacrebleu")
def postprocess_text(preds, labels):
preds = [p.strip() for p in preds]
labels = [[l.strip()] for l in labels]
return preds, labels
def compute_metrics(eval_pred):
preds, labels = eval_pred
preds = np.where(preds != -100, preds, tok.pad_token_id)
decoded_preds = tok.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tok.pad_token_id)
decoded_labels = tok.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = bleu.compute(predictions=decoded_preds, references=decoded_labels)
return {"sacrebleu": result["score"]}
Step 6: Train (a few steps for demo)
Fine-tunes the model quickly; prints sacreBLEU to gauge quality.
args = TrainingArguments(
output_dir="mt-enfr-demo",
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
learning_rate=2e-5,
num_train_epochs=1, # demo; increase for real runs
evaluation_strategy="epoch",
fp16=True,
save_total_limit=1,
logging_steps=50,
report_to="none"
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_tok,
eval_dataset=test_tok,
tokenizer=tok,
data_collator=data_collator,
compute_metrics=compute_metrics
)
trainer.train()
eval_metrics = trainer.evaluate()
print(eval_metrics)
Step 7: Inference (pipeline-style)
Generates translations using your fine-tuned checkpoint.
from transformers import pipeline
translator = pipeline("translation", model=model, tokenizer=tok)
print(translator("where is the central station?"))
Step 8: (Optional) Beam search & length normalization
Demonstrates decoding knobs used in large-scale MT like GNMT (beam, length penalty).
# Using generation kwargs to mimic production decoding choices
txt = "the warranty does not cover water damage."
inputs = tok([txt], return_tensors="pt")
gen = model.generate(
**inputs, num_beams=5, length_penalty=0.8, max_new_tokens=64, early_stopping=True
)
print(tok.batch_decode(gen, skip_special_tokens=True)[0])
Quick Reference: Full Code
# realworld_marianmt_finetune_en_fr.py
# Fine-tune MarianMT (EN→FR) with Hugging Face + evaluate with sacreBLEU
# (In a fresh environment)
# pip install -q transformers datasets accelerate evaluate sacrebleu
import numpy as np, torch
from datasets import load_dataset
from transformers import (
AutoTokenizer, AutoModelForSeq2SeqLM,
DataCollatorForSeq2Seq, TrainingArguments, Trainer, pipeline
)
import evaluate
device = "cuda" if torch.cuda.is_available() else "cpu"
fp16 = torch.cuda.is_available()
# -----------------------
# Data
# -----------------------
# Small parallel corpus for demo
raw = load_dataset("opus_books", "en-fr")
split = raw["train"].train_test_split(test_size=0.1, seed=42)
train_ds, test_ds = split["train"], split["test"]
# -----------------------
# Model & Tokenizer
# -----------------------
model_name = "Helsinki-NLP/opus-mt-en-fr"
tok = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# -----------------------
# Preprocess
# -----------------------
src_lang, tgt_lang = "en", "fr"
max_len = 128
def preprocess(batch):
src = [ex[src_lang] for ex in batch["translation"]]
tgt = [ex[tgt_lang] for ex in batch["translation"]]
model_inputs = tok(src, max_length=max_len, truncation=True)
labels = tok(text_target=tgt, max_length=max_len, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
train_tok = train_ds.map(preprocess, batched=True, remove_columns=train_ds.column_names)
test_tok = test_ds.map(preprocess, batched=True, remove_columns=test_ds.column_names)
# -----------------------
# Collator & Metrics (sacreBLEU)
# -----------------------
data_collator = DataCollatorForSeq2Seq(tok, model=model)
metric = evaluate.load("sacrebleu")
def postprocess_text(preds, labels):
preds = [p.strip() for p in preds]
labels = [[l.strip()] for l in labels]
return preds, labels
def compute_metrics(eval_pred):
preds, labels = eval_pred
# When predict_with_generate=True, preds are generated sequences
decoded_preds = tok.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tok.pad_token_id)
decoded_labels = tok.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
return {"sacrebleu": result["score"]}
# -----------------------
# Training
# -----------------------
args = TrainingArguments(
output_dir="mt-enfr-demo",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=1, # increase for real use
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=1,
logging_steps=50,
predict_with_generate=True, # generate during eval for BLEU
generation_max_length=128,
generation_num_beams=4,
fp16=fp16,
report_to="none",
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_tok,
eval_dataset=test_tok,
tokenizer=tok,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
metrics = trainer.evaluate()
print("Eval metrics:", metrics)
# -----------------------
# Inference
# -----------------------
translate = pipeline("translation", model=model, tokenizer=tok, device=0 if device=="cuda" else -1)
examples = [
"Where is the central station?",
"The warranty does not cover water damage.",
"Thank you for your help."
]
for s in examples:
print(s, "->", translate(s)[0]["translation_text"])
# Optional: custom decoding controls
txt = "Please read the safety instructions before use."
inputs = tok([txt], return_tensors="pt").to(model.device)
gen = model.generate(**inputs, num_beams=5, length_penalty=0.8, max_new_tokens=64, early_stopping=True)
print("Beam(5) ->", tok.batch_decode(gen, skip_special_tokens=True)[0])
Strengths & Limitations
Strengths
- General framework for sequence transduction: works for MT, summarization, captioning, dialogue, etc.
- Attention provides interpretability and better long-range handling compared to fixed-vector bottlenecks.
- Transfer learning friendly: pre-trained Seq2Seq (e.g., MarianMT, T5, BART) can be efficiently fine-tuned for domains.
Limitations
- Latency & decoding cost: autoregressive generation plus beam search can be slow; batching and quantization help.
- Data/domain shift sensitivity: quality drops on out-of-domain text; requires domain adaptation and robust tokenization.
- RNN-based Seq2Seq underperforms Transformers at scale (speed/quality), though it’s excellent pedagogically.
Final Notes
You built a full Seq2Seq pipeline from first principles: encoder–decoder, attention, teacher forcing, greedy/beam decoding, and BLEU evaluation. Then you switched to a production-style approach by fine-tuning a pre-trained MarianMT model—exactly how modern MT teams accelerate delivery.
These foundations make it straightforward to graduate to Transformers without changing the overall workflow (prepare data → tokenize → train/fine-tune → decode → evaluate).
Next Steps for You:
- Upgrade to Transformers: re-implement the toy system with a minimal Transformer encoder–decoder; compare training time and BLEU.
- Coverage & alignment visualization: log attention maps and experiment with coverage penalties/length normalization; study error modes (over-translation vs. under-translation).
- Subword experiments: swap in SentencePiece WordPiece/BPE tokenization and measure rare-word handling on names/morphology.
References
[1] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to Sequence Learning with Neural Networks,” Advances in Neural Information Processing Systems (NeurIPS), 2014.
[2] D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” arXiv:1409.0473, 2014/2015.
[3] M.-T. Luong, H. Pham, and C. D. Manning, “Effective Approaches to Attention-based Neural Machine Translation,” EMNLP, 2015. Stanford NLPACL Anthology
[4] A. Vaswani et al., “Attention Is All You Need,” NeurIPS, 2017.
[5] Y. Wu et al., “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation,” arXiv:1609.08144, 2016.
[6] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: a Method for Automatic Evaluation of Machine Translation,” Proc. ACL, 2002.

Leave a comment