
Next-Word Prediction → Chat Autocomplete
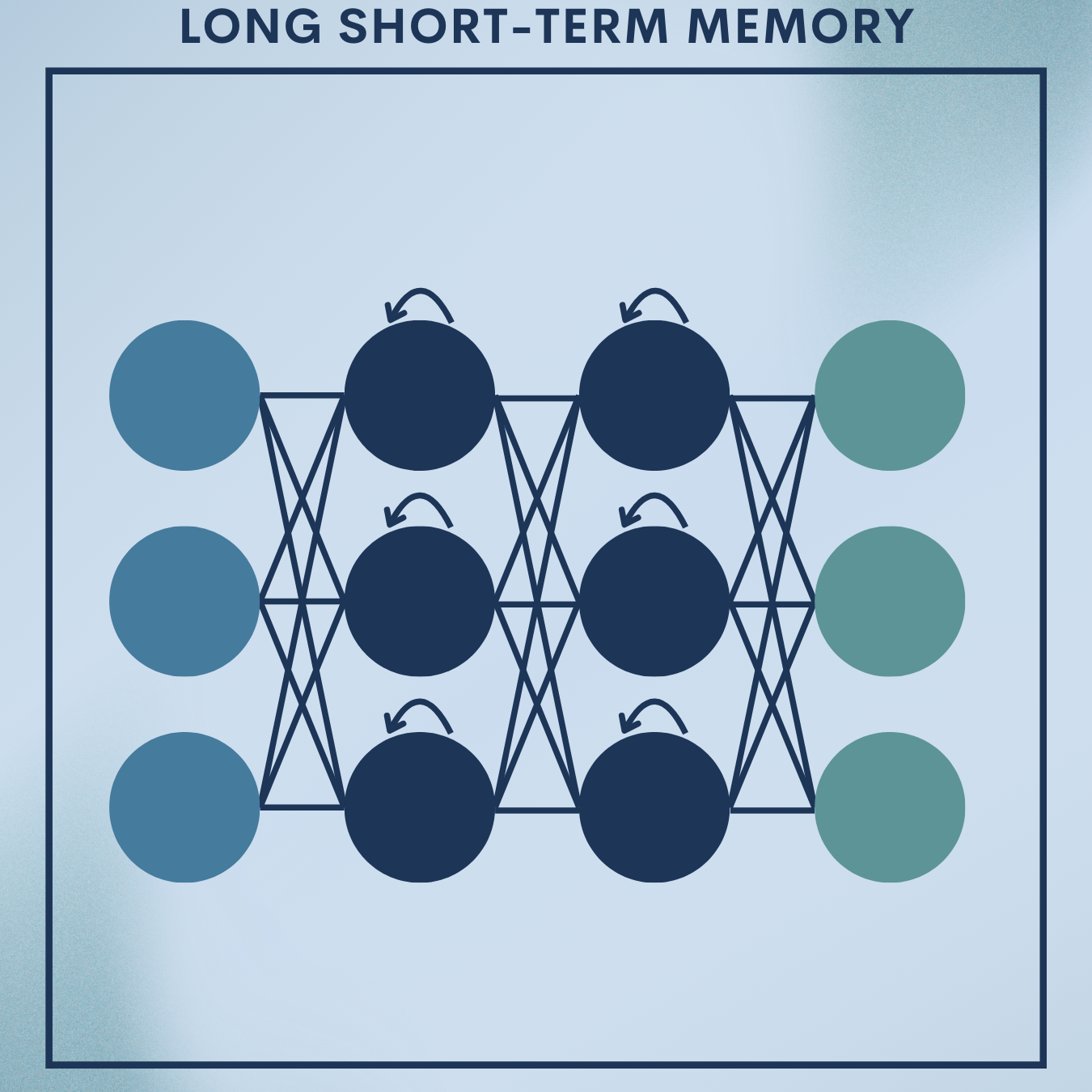
Why LTSM?
If you’ve ever watched your phone suggest the next word as you type, or your IDE predict the next token while you code, you’ve used sequence models. Among the classic workhorses is the LSTM—a recurrent neural network (RNN) variant that uses gates to decide what to remember and what to forget, allowing it to model long-range dependencies far better than vanilla RNNs.
What you’ll build today
- Toy problem: a small next-word predictor trained on a tiny corpus so you can see every moving part—tokenization, windowed sequences, batching, LSTM modeling, training, evaluation (perplexity), and sampling with temperature/top-k.
- Real-world application: a chat autocomplete prototype that suggests the next word and can auto-complete a line using the same LSTM backbone, wrapped in a minimal interactive function you can hook into a UI later.
Where this is used
- Mobile keyboards and messaging apps (predictive text, auto-complete)
- Customer support tools (agent reply drafting)
- IDEs and command lines (token/word suggestions)
Theory Deep Dive
1. Problem Formulation
Given a token sequence 


We typically feed embedded tokens:![e_t = E[x_t] \in \mathbb{R}^{d}](https://s0.wp.com/latex.php?latex=e_t+%3D+E%5Bx_t%5D+%5Cin+%5Cmathbb%7BR%7D%5E%7Bd%7D&bg=ffffff&fg=000&s=0&c=20201002)



2. Vanilla RNN
A simple RNN updates its hidden state as:
This suffers from vanishing/exploding gradients over long sequences, making it hard to learn long-range patterns.
3. LSTM cell
The LSTM introduces a cell state 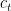
- Input gate:
- Forget gate:
- Candidate: $latex \tilde{c}t = \tanh(W_c e_t + U_c h{t-1} + b_c)$
- Cell update:
- Output gate:
- Hidden state:





Here 
4. Output layer and training objective
At each step:

We minimize cross-entropy:
Perplexity is a common metric:
5. Teacher forcing, truncated BPTT
Teacher forcing: during training, feed the true previous token (faster convergence).
Truncated BPTT: backprop through limited timesteps (e.g., 30–100) for efficiency.
6. Practical considerations
Tokenization. For pedagogy we’ll use whitespace+punctuation split (word-level). In production, subword (BPE/WordPiece) improves OOV handling.
Batching & padding. Fixed windows (e.g., 20 tokens) → pad shorter sequences, mask pads in the loss.
Regularization. Dropout on embeddings or between LSTM layers; gradient clipping (e.g., 1.0) for stability.
Hyperparameters. Embedding dim 128–512; hidden size 256–1024; 1–2 layers; Adam with 

Sampling strategies.
- Greedy: pick argmax (can be repetitive).
- Temperature:
(softer for
).
- Top-k: restrict to top k tokens.
- Nucleus (top-p): minimal set with cumulative prob ≥ p.
- Beam search: joint sequence search (more expensive).
Layer variants. Peephole LSTM, LayerNorm LSTM, GRU (simpler), or stacked LSTMs.
Where LSTMs sit today. Transformers dominate large-scale language tasks, but LSTMs remain excellent for small/medium data, on-device inference, and scenarios favoring compact models and low latency.
Toy Problem – Next-Word Prediction (tiny corpus)
Goal: Implement the end-to-end pipeline on a tiny corpus to demystify each step.
Data Snapshot
We’ll use a small list of sentences to keep things transparent:
the quick brown fox jumps over the lazy dog
i love deep learning
lstm networks remember long context
sequence models predict the next word
pytorch makes building models simple
After lowercasing + simple tokenization, suppose we get:
- Vocabulary (example):
['<PAD>','<UNK>','the','quick','brown','fox','jumps','over','lazy','dog','i','love','deep','learning','lstm','networks','remember','long','context','sequence','models','predict','next','word','pytorch','makes','building','simple'] - Vocab size (V): around 27–35 depending on tokenizer
- Sequence window (L): e.g., 5 input tokens → predict the 6th
- Number of training sequences: depends on sliding windows ($\approx$ sum over sentences of (tokens−L))
We’ll show one training pair (X → y):
- X:
['sequence','models','predict','the','next'] - y:
'word'
Step 1: Environment & imports
Note: Breakpoints are small; each block has a 1–2 sentence explanation. You can paste these into a Colab/Notebook.
Define the tiny corpus and imports. We’ll keep everything deterministic with a fixed seed.
import re, math, random, itertools
from collections import Counter
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
torch.manual_seed(42)
sentences = [
"the quick brown fox jumps over the lazy dog",
"i love deep learning",
"lstm networks remember long context",
"sequence models predict the next word",
"pytorch makes building models simple",
]
Step 2: Tokenization & vocabulary
Simple regex tokenization; build a minimal vocabulary. We reserve indices for <PAD> and <UNK>.
def tokenize(s):
return re.findall(r"[a-zA-Z']+|[.,!?;]", s.lower())
UNK, PAD = "<UNK>", "<PAD>"
tokens = list(itertools.chain.from_iterable(tokenize(s) for s in sentences))
vocab_counts = Counter(tokens)
itos = [PAD, UNK] + sorted(vocab_counts.keys())
stoi = {w:i for i,w in enumerate(itos)}
V = len(itos)
Step 3: Encode and make (X, y) windows
Turn sentences into sliding windows of length L; each window predicts the next token. Split small validation set.
def encode(tokens):
return [stoi.get(t, stoi[UNK]) for t in tokens]
L = 5 # input length (window)
pairs = []
for s in sentences:
toks = tokenize(s)
ids = encode(toks)
if len(ids) <= L:
continue
for i in range(len(ids)-L):
X = ids[i:i+L]
y = ids[i+L]
pairs.append((X, y))
random.shuffle(pairs)
n_val = max(1, len(pairs)//5)
val_pairs = pairs[:n_val]
train_pairs = pairs[n_val:]
Step 4: Dataset & DataLoader
Wrap training pairs in a Dataset/Dataloader for batching and shuffling.
class NWPairs(Dataset):
def __init__(self, pairs):
self.pairs = pairs
def __len__(self):
return len(self.pairs)
def __getitem__(self, idx):
X, y = self.pairs[idx]
return torch.tensor(X, dtype=torch.long), torch.tensor(y, dtype=torch.long)
train_ds, val_ds = NWPairs(train_pairs), NWPairs(val_pairs)
train_dl = DataLoader(train_ds, batch_size=16, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=16)
Step 5: LSTM language model
A single-layer LSTM maps the last hidden state to next-token logits. We use cross-entropy and Adam.
class LSTMLM(nn.Module):
def __init__(self, vocab_size, d_emb=128, d_hid=256, n_layers=1, p_drop=0.2):
super().__init__()
self.emb = nn.Embedding(vocab_size, d_emb)
self.lstm = nn.LSTM(d_emb, d_hid, num_layers=n_layers, batch_first=True, dropout=p_drop if n_layers>1 else 0.0)
self.drop = nn.Dropout(p_drop)
self.fc = nn.Linear(d_hid, vocab_size)
def forward(self, x):
# x: (B, L)
e = self.emb(x) # (B, L, d_emb)
h,_ = self.lstm(e) # (B, L, d_hid)
h_last = h[:,-1,:] # (B, d_hid)
logits = self.fc(self.drop(h_last)) # (B, V)
return logits
model = LSTMLM(V)
criterion = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
Step 6: Training & evaluation (loss + perplexity)
Train for a few epochs and report negative log-likelihood (NLL) and perplexity (PPL).
def epoch_loop(dl, train=True):
model.train(train)
total_nll, total_n = 0.0, 0
for X, y in dl:
if train:
opt.zero_grad()
logits = model(X)
loss = criterion(logits, y)
if train:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
opt.step()
total_nll += loss.item() * X.size(0)
total_n += X.size(0)
avg_nll = total_nll / total_n
ppl = math.exp(avg_nll)
return avg_nll, ppl
for epoch in range(30):
tr_nll, tr_ppl = epoch_loop(train_dl, train=True)
va_nll, va_ppl = epoch_loop(val_dl, train=False)
if (epoch+1)%5==0:
print(f"Epoch {epoch+1:02d} | train NLL {tr_nll:.3f} PPL {tr_ppl:.2f} | val NLL {va_nll:.3f} PPL {va_ppl:.2f}")
Step 7: Sampling helpers (temperature + top-k)
Provide top-k suggestions for the next word and a simple auto-complete with temperature-scaled sampling.
import torch.nn.functional as F
def top_k_logits(logits, k):
v, ix = torch.topk(logits, k)
out = torch.full_like(logits, -float('inf'))
out.scatter_(dim=-1, index=ix, src=v)
return out
def predict_next(token_ids, k=5, temperature=1.0):
x = torch.tensor([token_ids[-L:]], dtype=torch.long)
logits = model(x)[0] / temperature
probs = F.softmax(logits, dim=-1)
topk = torch.topk(probs, k)
return [(itos[i.item()], topk.values[j].item()) for j,i in enumerate(topk.indices)]
def complete(prefix, max_tokens=10, temperature=0.8, k=10):
toks = tokenize(prefix)
ids = encode(toks)
out = toks[:]
for _ in range(max_tokens):
x = torch.tensor([ids[-L:]], dtype=torch.long)
logits = model(x)[0] / temperature
logits = top_k_logits(logits, k)
probs = F.softmax(logits, dim=-1)
next_id = torch.multinomial(probs, num_samples=1).item()
out.append(itos[next_id])
ids.append(next_id)
return " ".join(out)
Step 8: Quick sanity check
Try a prefix and see the model’s suggestions and an auto-completion.
seed = "sequence models predict the"
print("Next-word suggestions:", predict_next(encode(tokenize(seed)), k=5, temperature=0.8))
print("Autocomplete:", complete(seed, max_tokens=5, temperature=0.8, k=10))
Quick Reference: Full Code
# === Toy Next-Word LSTM (Compact) ===
import re, math, random, itertools, torch
from collections import Counter
from torch import nn
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
torch.manual_seed(42)
sentences = [
"the quick brown fox jumps over the lazy dog",
"i love deep learning",
"lstm networks remember long context",
"sequence models predict the next word",
"pytorch makes building models simple",
]
def tokenize(s): return re.findall(r"[a-zA-Z']+|[.,!?;]", s.lower())
UNK, PAD = "<UNK>", "<PAD>"
tokens = list(itertools.chain.from_iterable(tokenize(s) for s in sentences))
itos = [PAD, UNK] + sorted(Counter(tokens).keys())
stoi = {w:i for i,w in enumerate(itos)}
def encode(tokens): return [stoi.get(t, stoi[UNK]) for t in tokens]
V, L = len(itos), 5
pairs = []
for s in sentences:
ids = encode(tokenize(s))
for i in range(max(0, len(ids)-L)):
pairs.append((ids[i:i+L], ids[i+L]))
random.shuffle(pairs)
val_pairs, train_pairs = pairs[:max(1,len(pairs)//5)], pairs[max(1,len(pairs)//5):]
class NWPairs(Dataset):
def __init__(self, P): self.P = P
def __len__(self): return len(self.P)
def __getitem__(self, i): X,y = self.P[i]; return torch.tensor(X), torch.tensor(y)
train_dl, val_dl = DataLoader(NWPairs(train_pairs),16,True), DataLoader(NWPairs(val_pairs),16)
class LSTMLM(nn.Module):
def __init__(self, V, d=128, h=256):
super().__init__()
self.emb=nn.Embedding(V,d); self.lstm=nn.LSTM(d,h,batch_first=True)
self.fc=nn.Linear(h,V)
def forward(self,x):
h,_=self.lstm(self.emb(x)); return self.fc(h[:,-1,:])
model=LSTMLM(V); opt=torch.optim.Adam(model.parameters(),1e-3); crit=nn.CrossEntropyLoss()
def run(dl,train=True):
model.train(train); tot=0; n=0
for X,y in dl:
if train: opt.zero_grad()
loss=crit(model(X), y)
if train: loss.backward(); nn.utils.clip_grad_norm_(model.parameters(),1.0); opt.step()
tot += loss.item()*X.size(0); n += X.size(0)
nll=tot/n; return nll, math.exp(nll)
for e in range(30):
tr=run(train_dl,True); va=run(val_dl,False)
if (e+1)%5==0: print(f"{e+1:02d} | tr PPL {tr[1]:.2f} | va PPL {va[1]:.2f}")
def top_k_logits(logits,k):
v,ix=torch.topk(logits,k); out=torch.full_like(logits,-float('inf')); out.scatter_(1,ix,v); return out
def predict_next(token_ids,k=5,tau=1.0):
x=torch.tensor([token_ids[-L:]]); logits=model(x)[0]/tau; p=torch.softmax(logits,0)
v,ix=torch.topk(p,k); return [(itos[ix[i].item()], v[i].item()) for i in range(k)]
def complete(prefix,steps=10,tau=0.8,k=10):
toks=tokenize(prefix); ids=encode(toks); out=toks[:]
for _ in range(steps):
x=torch.tensor([ids[-L:]]); logits=model(x)[0]/tau; logits=top_k_logits(logits.unsqueeze(0),k)[0]
p=torch.softmax(logits,0); nid=torch.multinomial(p,1).item()
out.append(itos[nid]); ids.append(nid)
return " ".join(out)
print(complete("sequence models predict the",5))
Real‑World Application — Chat Autocomplete (prototype)
We’ll extend the pipeline to a chat dataset (format-agnostic). You can bring your CSV of past chats or support tickets. We’ll assume a CSV with two columns:
speaker∈ {user,agent}text= message content
We’ll build a single vocabulary across both speakers and add special tokens like <BOS>, <EOS>, <USER>, <AGENT>.
Data Snapshot
First 5 rows sample
| speaker | text |
|---|---|
| user | hi, i need help with my order |
| agent | sure, can you share your order id? |
| user | 12345 |
| agent | thanks! i see the issue now |
| user | great, what should i do next |
Tokenization example (one line):
<USER> hi , i need help with my order <EOS>
Step 1: Imports & configuration
This mirrors the toy pipeline but adds speaker tags, dropout, two LSTM layers, and serving helpers.
Configure dataset path and hyperparameters; increase epochs for larger corpora.
import re, csv, math, random
from collections import Counter
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
torch.manual_seed(7)
DATA_PATH = "chat_sample.csv" # your CSV with columns: speaker,text
SPECIAL = ["<PAD>","<UNK>","<BOS>","<EOS>","<USER>","<AGENT>"]
L = 15 # context length (tokens to look back)
BATCH = 64
EPOCHS = 5 # increase for real training
Step 2: Load & tokenize
Read CSV and add speaker + sentence boundary tokens.
def tokenize(s): return re.findall(r"[a-zA-Z']+|[.,!?;]", s.lower())
def load_chat_rows(path):
rows=[]
with open(path, newline='', encoding='utf-8') as f:
r=csv.DictReader(f)
for row in r:
sp = row["speaker"].strip().lower()
sp_tok = "<USER>" if sp=="user" else "<AGENT>"
toks = [sp_tok, "<BOS>"] + tokenize(row["text"]) + ["<EOS>"]
rows.append(toks)
return rows
rows = load_chat_rows(DATA_PATH)
Step 3: Vocabulary & encoding
Build a shared vocabulary and encoding functions.
cnt = Counter(t for toks in rows for t in toks)
itos = SPECIAL + sorted([t for t in cnt if t not in SPECIAL])
stoi = {w:i for i,w in enumerate(itos)}
V = len(itos)
def encode(toks): return [stoi.get(t, stoi["<UNK>"]) for t in toks]
Step 4: Create training sequences (sliding windows)
Window the chat lines into (context → next token) pairs; split train/validation.
pairs=[]
for toks in rows:
ids = encode(toks)
if len(ids) <= L:
continue
for i in range(len(ids)-L):
X = ids[i:i+L]
y = ids[i+L]
pairs.append((X,y))
random.shuffle(pairs)
n_val = max(200, int(0.1*len(pairs)))
val_pairs = pairs[:n_val]; train_pairs = pairs[n_val:]
Step 5: Dataset & DataLoader
Standard PyTorch dataset for chat sequences.
class ChatPairs(Dataset):
def __init__(self, P): self.P=P
def __len__(self): return len(self.P)
def __getitem__(self, i):
X,y = self.P[i]
return torch.tensor(X), torch.tensor(y)
train_dl = DataLoader(ChatPairs(train_pairs), batch_size=BATCH, shuffle=True)
val_dl = DataLoader(ChatPairs(val_pairs), batch_size=BATCH)
Step 6: Stacked LSTM model (2 layers + dropout)
A 2-layer LSTM often improves modeling power for language tasks; dropout regularizes.
class ChatLSTMLM(nn.Module):
def __init__(self, V, d_emb=256, d_hid=512, n_layers=2, p_drop=0.3):
super().__init__()
self.emb = nn.Embedding(V, d_emb)
self.lstm = nn.LSTM(d_emb, d_hid, num_layers=n_layers, batch_first=True, dropout=p_drop)
self.drop = nn.Dropout(p_drop)
self.fc = nn.Linear(d_hid, V)
def forward(self, x):
e = self.emb(x) # (B, L, d_emb)
h,_ = self.lstm(e) # (B, L, d_hid)
hL = h[:,-1,:] # (B, d_hid)
return self.fc(self.drop(hL)) # (B, V)
model = ChatLSTMLM(V)
opt = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
Step 7: Train & evaluate
Report perplexity to track learning; expect improvements with more data/epochs.
def loop(dl, train=True):
model.train(train)
total, n = 0.0, 0
for X,y in dl:
if train: opt.zero_grad()
logits = model(X)
loss = criterion(logits, y)
if train:
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
opt.step()
total += loss.item() * X.size(0)
n += X.size(0)
nll = total/n
return nll, math.exp(nll)
for epoch in range(EPOCHS):
tr = loop(train_dl, True)
va = loop(val_dl, False)
print(f"Epoch {epoch+1}/{EPOCHS} | train PPL {tr[1]:.2f} | val PPL {va[1]:.2f}")
Step 8: Inference helpers (suggest next word, autocomplete a reply)
Generate top-k next-word suggestions and a short auto-completed line conditioned on the speaker tag.
def top_k_logits(logits, k):
v, ix = torch.topk(logits, k)
out = torch.full_like(logits, -float('inf'))
out.scatter_(dim=-1, index=ix, src=v)
return out
def suggest_next(prefix_tokens, k=5, temperature=0.8):
ids = encode(prefix_tokens)
x = torch.tensor([ids[-L:]])
logits = model(x)[0] / temperature
probs = torch.softmax(logits, dim=-1)
v,ix = torch.topk(probs, k)
return [(itos[ix[i].item()], v[i].item()) for i in range(k)]
def autocomplete_line(speaker="user", prompt="hi i need", max_new=12, temperature=0.8, k=10, stop_token="<EOS>"):
toks = [ "<USER>" if speaker=="user" else "<AGENT>", "<BOS>" ] + tokenize(prompt)
ids = encode(toks)
out = toks[:]
for _ in range(max_new):
x = torch.tensor([ids[-L:]])
logits = model(x)[0] / temperature
logits = top_k_logits(logits.unsqueeze(0), k)[0]
probs = torch.softmax(logits, dim=-1)
nid = torch.multinomial(probs, 1).item()
tok = itos[nid]
out.append(tok); ids.append(nid)
if tok == stop_token:
break
# strip BOS/EOS in display
return " ".join([t for t in out if t not in ("<BOS>","<EOS>")])
Step 9: Example calls
Quickly test on a user prompt and an agent prompt.
print("Suggestions:", suggest_next(["<USER>","<BOS>","hi",",","i","need"]))
print("Autocomplete:", autocomplete_line(speaker="agent", prompt="sure, please", max_new=10))
Step 10: (Optional) Lightweight safety filter
Filtering isn’t perfect but can remove known undesired tokens. For production, use a robust moderation layer.
BANNED = {"badword1","badword2"} # extend with your list
def safe_suggestions(prefix_tokens, **kw):
sug = suggest_next(prefix_tokens, **kw)
return [(w,p) for (w,p) in sug if w not in BANNED]
Quick Reference: Full Code
# === Chat Autocomplete LSTM (Compact) ===
import re, csv, math, random, torch
from collections import Counter
from torch import nn
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
torch.manual_seed(7)
DATA_PATH="chat_sample.csv"; SPECIAL=["<PAD>","<UNK>","<BOS>","<EOS>","<USER>","<AGENT>"]; L=15; BATCH=64; EPOCHS=5
def tokenize(s): return re.findall(r"[a-zA-Z']+|[.,!?;]", s.lower())
def load_rows(p):
rows=[]
with open(p, newline='', encoding='utf-8') as f:
r=csv.DictReader(f)
for row in r:
sp = "<USER>" if row["speaker"].strip().lower()=="user" else "<AGENT>"
rows.append([sp,"<BOS>"]+tokenize(row["text"]) + ["<EOS>"])
return rows
rows=load_rows(DATA_PATH)
cnt=Counter(t for toks in rows for t in toks)
itos = SPECIAL + sorted([t for t in cnt if t not in SPECIAL]); stoi={w:i for i,w in enumerate(itos)}
def enc(ts): return [stoi.get(t, stoi["<UNK>"]) for t in ts]
V=len(itos)
pairs=[]
for toks in rows:
ids=enc(toks)
for i in range(max(0,len(ids)-L)):
pairs.append((ids[i:i+L], ids[i+L]))
random.shuffle(pairs)
val_pairs, train_pairs = pairs[:max(200,int(0.1*len(pairs)))], pairs[max(200,int(0.1*len(pairs))):]
class Pairs(Dataset):
def __init__(self,P): self.P=P
def __len__(self): return len(self.P)
def __getitem__(self,i): X,y=self.P[i]; return torch.tensor(X), torch.tensor(y)
train_dl, val_dl = DataLoader(Pairs(train_pairs),BATCH,True), DataLoader(Pairs(val_pairs),BATCH)
class LM(nn.Module):
def __init__(self,V,d=256,h=512):
super().__init__(); self.emb=nn.Embedding(V,d); self.lstm=nn.LSTM(d,h,2,batch_first=True,dropout=0.3); self.fc=nn.Linear(h,V)
def forward(self,x): h,_=self.lstm(self.emb(x)); return self.fc(h[:,-1,:])
m=LM(V); opt=torch.optim.Adam(m.parameters(),1e-3); crit=nn.CrossEntropyLoss()
def loop(dl,train=True):
m.train(train); tot=0;n=0
for X,y in dl:
if train: opt.zero_grad()
loss=crit(m(X),y)
if train: loss.backward(); nn.utils.clip_grad_norm_(m.parameters(),1.0); opt.step()
tot+=loss.item()*X.size(0); n+=X.size(0)
nll=tot/n; return nll, math.exp(nll)
for e in range(EPOCHS):
tr=loop(train_dl,True); va=loop(val_dl,False)
print(f"{e+1}/{EPOCHS} PPL tr {tr[1]:.2f} va {va[1]:.2f}")
def top_k_logits(logits,k):
v,ix=torch.topk(logits,k); out=torch.full_like(logits,-float('inf')); out.scatter_(1,ix,v); return out
def suggest_next(prefix, k=5, tau=0.8):
ids=enc(prefix); x=torch.tensor([ids[-L:]]); logits=m(x)[0]/tau; p=torch.softmax(logits,0); v,ix=torch.topk(p,k)
return [(itos[ix[i].item()], v[i].item()) for i in range(k)]
def autocomplete_line(speaker="user", prompt="hi", steps=12, tau=0.8, k=10):
toks=[ "<USER>" if speaker=="user" else "<AGENT>", "<BOS>" ]+tokenize(prompt)
ids=enc(toks); out=toks[:]
for _ in range(steps):
logits=m(torch.tensor([ids[-L:]]))[0]/tau
logits=top_k_logits(logits.unsqueeze(0),k)[0]
p=torch.softmax(logits,0); nid=torch.multinomial(p,1).item()
tok=itos[nid]; out.append(tok); ids.append(nid)
if tok=="<EOS>": break
return " ".join([t for t in out if t not in ("<BOS>","<EOS>")])
print(autocomplete_line("agent","sure, please"))
Strengths & Limitations
Strengths
- Handles longer dependencies than vanilla RNNs via gated cell state updates.
- Data-efficient and compact compared to large Transformers; good for small/edge deployments.
- Stable training with truncated BPTT, dropout, and gradient clipping.
Limitations
- Still struggles with very long contexts (hundreds/thousands of tokens); attention mechanisms scale better.
- Sequential computation limits parallelism (slower training/inference than Transformers on large corpora).
- Vocabulary/OOV handling is weaker with word-level tokenization unless using subword models.
Final Notes
You built a complete LSTM language modeling pipeline—from tokenization and dataset construction to model training, evaluation with perplexity, and sampling strategies (temperature/top-k).
You then adapted the same backbone to a chat autocomplete scenario, layering on speaker tags and a minimal inference API for next-word suggestions and auto-completion. This pattern generalizes: the core is a conditional next-token model; the application is how you package it (keyboard, chat box, code editor, CLI).
Next Steps for You:
- Upgrade tokenization & data scale. Switch to a subword tokenizer (SentencePiece/BPE) and train on a larger, domain-specific corpus to reduce OOVs and improve suggestions.
- Enhance decoding & UX. Add nucleus (top-p) sampling and beam search, log keystroke latencies, and build a small UI (Gradio/Streamlit) to measure suggestion acceptance rate.
(Stretch ideas: weight tying, LayerNorm LSTMs, bidirectional encoders for fill-in-the-middle, or migrating to a small Transformer for comparison.)
References
[1] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
[2] A. Graves, “Generating Sequences With Recurrent Neural Networks,” arXiv:1308.0850, 2013.
[3] T. Mikolov, M. Karafiát, L. Burget, J. Černocký, and S. Khudanpur, “Recurrent Neural Network Based Language Model,” in INTERSPEECH, 2010.
[4] Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin, “A Neural Probabilistic Language Model,” JMLR, vol. 3, pp. 1137–1155, 2003.
[5] R. Jozefowicz, W. Zaremba, and I. Sutskever, “An Empirical Exploration of Recurrent Network Architectures,” ICML, 2015.
[6] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to Sequence Learning with Neural Networks,” NeurIPS, 2014.
[7] A. Holtzman, J. Buys, M. Forbes, and Y. Choi, “The Curious Case of Neural Text Degeneration,” ICLR, 2020.
[8] P. Y. Gal and Z. Ghahramani, “A Theoretically Grounded Application of Dropout in Recurrent Neural Networks,” NeurIPS, 2016.
[9] PyTorch, “torch.nn.LSTM — PyTorch Docs.”
[10] F. Chollet et al., “Keras Documentation: Recurrent Layers,” keras.io.

Leave a comment