
Toy Question–Answer Dataset → Customer Support Chatbots
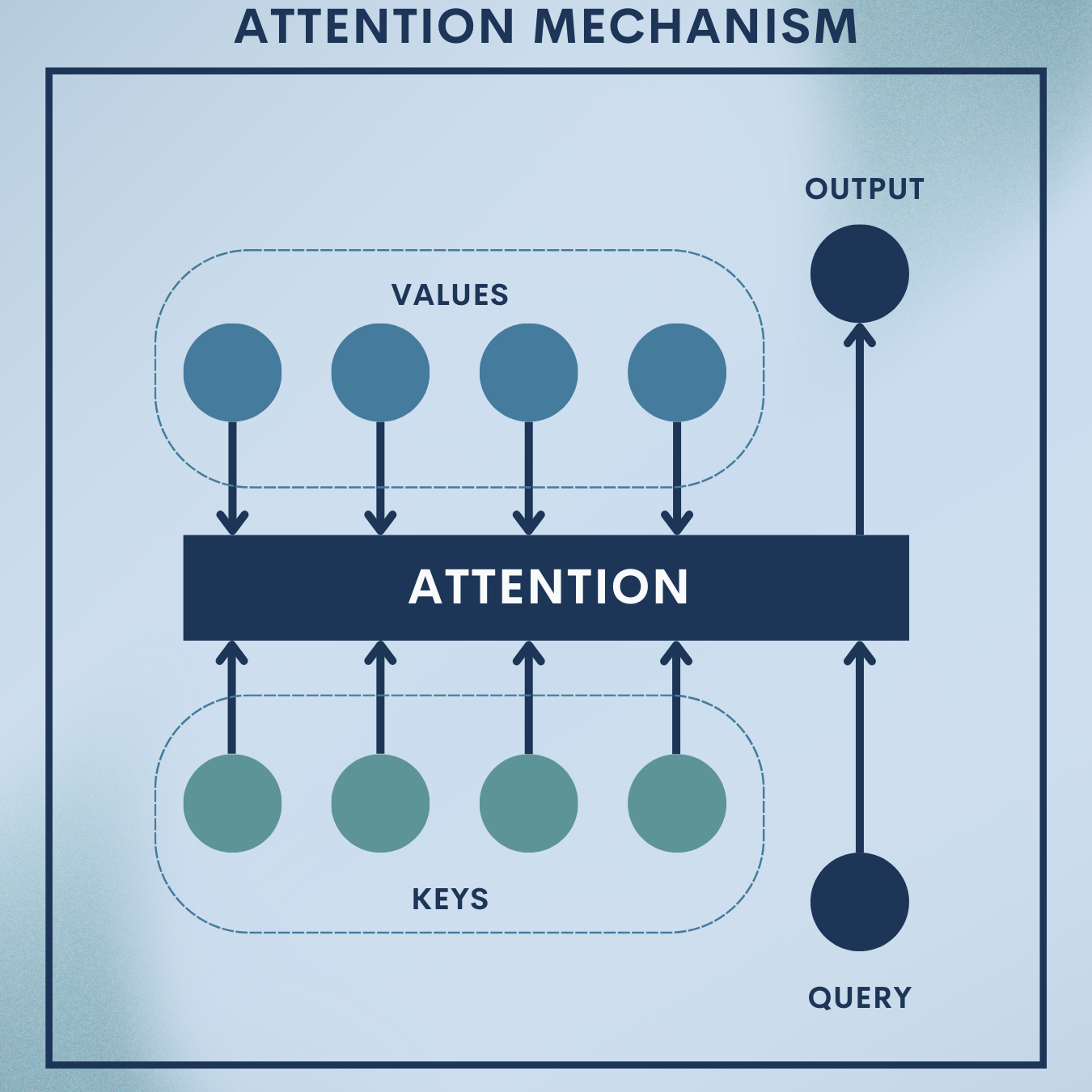
Why Attention Mechanisms?
In long sequences, a model easily “forgets” early tokens or crams everything into a single fixed-size vector. Attention fixes that by letting the model selectively look back at the most relevant parts of the input—on every decoding step. For question answering (QA), attention acts like a spotlight over the passage: when asked “What is the order status?”, the model learns to focus on “status is processing.”
In this article you’ll:
- Build a small seq2seq with attention for a toy QA task (passage + question → short answer).
- Extend it into a customer support chatbot scaffold that retrieves a relevant FAQ paragraph and uses attention to generate a concise reply.
- Learn the math behind additive, multiplicative, and scaled dot-product attention, and when to use which.
Theory Deep Dive
1. Encoder–Decoder Bottleneck and Alignment
Classic seq2seq encodes an input sequence 



- Encoder hidden states:
for
- Decoder state at step
- Alignment (energy) function:
- Attention weights (softmax over source positions):
- Context vector (weighted sum of encoder states):
$latex \mathbf{c}t = \sum{i=1}^n \alpha_{t,i},\mathbf{h}_i$




The decoder then predicts token 
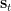

2. Score Functions (Bahdanau vs. Luong)
Common 
- Dot product (Luong):
- General (Luong):
- Additive (Bahdanau):



Bahdanau is a small MLP; Luong dot/general are simpler and fast.
3. Scaled Dot-Product & Multi-Head Self-Attention (Transformers)
Transformers use queries 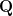

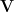

Multi-head attention splits dimensions and attends in parallel:


Self-attention sets 

4. Masks, Positions, and Complexity
Masks prevent attending to pads or future tokens (causal decoding).
Positional encoding injects order since self-attention is permutation-invariant.
Complexity is 
5. Loss, Training Dynamics, and Interpretability
Standard loss: token-level cross-entropy 
Teacher forcing stabilizes early training; gradually reduce to improve robustness.
Attention weights 
Toy Problem – Tiny Support-Style QA (Passage + Question → Short Answer)
We’ll synthesize a small QA dataset that looks like mini support notes. Each sample concatenates passage + a separator + question; the target is a short answer phrase.
Data Snapshot
| id | passage (truncated) | question | answer |
|---|---|---|---|
| 1 | order 1234 status is processing . payment received . | what is the order status ? | processing |
| 2 | password reset link expires in 24 hours . | how long before the link expires ? | 24 hours |
| 3 | refund is issued within 5 business days . | when is refund issued ? | 5 business days |
| 4 | delivery takes 3–5 days in metro manila . | how long is delivery ? | 3–5 days |
| 5 | support is available from 9 am to 6 pm . | what are support hours ? | 9 am to 6 pm |
We’ll use ~12–20 such items to keep training fast and illustrative.
Input format:
"passage <q> question"
Target format:"answer"(short phrase)
Step 1: Imports, seed, device
import math, random, re
import torch, torch.nn as nn
from torch.utils.data import Dataset, DataLoader
random.seed(7); torch.manual_seed(7)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Step 2: Build the toy QA pairs
Synthetic tiny dataset. Concatenates each passage and question with a special <q> token to signal the boundary.
RAW = [
("order 1234 status is processing . payment received .", "what is the order status ?", "processing"),
("password reset link expires in 24 hours .", "how long before the link expires ?", "24 hours"),
("refund is issued within 5 business days .", "when is refund issued ?", "5 business days"),
("delivery takes 3–5 days in metro manila .", "how long is delivery ?", "3–5 days"),
("support is available from 9 am to 6 pm .", "what are support hours ?", "9 am to 6 pm"),
("orders marked shipped cannot be cancelled .", "can a shipped order be cancelled ?", "no"),
("express shipping costs 150 php .", "how much is express shipping ?", "150 php"),
("standard shipping is free over 1000 php .", "when is shipping free ?", "over 1000 php"),
("warranty covers factory defects for 12 months .", "how long is the warranty ?", "12 months"),
("returns require original receipt .", "what is required for returns ?", "original receipt"),
("chat support response time is under 2 minutes .", "what is chat response time ?", "under 2 minutes"),
("opening hours are monday to saturday only .", "which days are open ?", "monday to saturday"),
]
SEP = "<q>" # question separator
pairs = [(f"{p} {SEP} {q}", a) for (p,q,a) in RAW]
Step 3: Tokenization & Vocabulary
Whitespace tokenization; add special tokens.
PAD, SOS, EOS, UNK = "<pad>", "<sos>", "<eos>", "<unk>"
def tokenize(s):
s = s.lower().strip()
s = re.sub(r"\s+", " ", s)
return s.split()
# build vocab
from collections import Counter
cnt = Counter()
for x,y in pairs:
cnt.update(tokenize(x)); cnt.update(tokenize(y))
itos = [PAD, SOS, EOS, UNK] + sorted([w for w,c in cnt.items() if c >= 1 and w not in {PAD,SOS,EOS,UNK}])
stoi = {w:i for i,w in enumerate(itos)}
def encode(tokens, add_eos=True):
ids = [stoi.get(t, stoi[UNK]) for t in tokens]
return ([stoi[SOS]] + ids + ([stoi[EOS]] if add_eos else []))
def pad_batch(seqs, pad=stoi[PAD]):
maxlen = max(len(s) for s in seqs)
out = [s + [pad]*(maxlen-len(s)) for s in seqs]
return torch.tensor(out)
Builds a minimal vocab and utilities to index and pad sequences; prepends <sos>, appends <eos>.
Step 4: Dataset & DataLoader
Wrap pairs into tensors.
class QADataset(Dataset):
def __init__(self, pairs):
self.pairs = pairs
def __len__(self): return len(self.pairs)
def __getitem__(self, i):
x_txt, y_txt = self.pairs[i]
x = encode(tokenize(x_txt))
y = encode(tokenize(y_txt))
return torch.tensor(x), torch.tensor(y)
def collate(batch):
xs, ys = zip(*batch)
return pad_batch(xs), pad_batch(ys)
ds = QADataset(pairs)
dl = DataLoader(ds, batch_size=4, shuffle=True, collate_fn=collate)
vocab_size = len(itos)
Creates batches of padded input/target index sequences.
Step 5: Encoder (BiGRU) with outputs
Encode the source once; keep all hidden states for attention.
class Encoder(nn.Module):
def __init__(self, vocab_size, emb=128, hid=256):
super().__init__()
self.emb = nn.Embedding(vocab_size, emb, padding_idx=stoi[PAD])
self.gru = nn.GRU(emb, hid, batch_first=True, bidirectional=True)
def forward(self, x):
# x: [B, S]
e = self.emb(x) # [B,S,E]
out, h = self.gru(e) # out: [B,S,2H], h: [2, B, H]
# concat directions into a single initial decoder state
h_cat = torch.cat([h[-2], h[-1]], dim=-1) # [B, 2H]
return out, h_cat
Embeds tokens and returns per-token states (for attention) plus a combined initial state for the decoder.
Step 6: Luong Dot-Product Attention
Compute alignment between decoder state and encoder outputs.
class LuongAttention(nn.Module):
def __init__(self, hid_enc2, hid_dec):
super().__init__()
# project encoder states to decoder dim if needed
self.lin = nn.Linear(hid_enc2, hid_dec, bias=False) if hid_enc2 != hid_dec else None
self.softmax = nn.Softmax(dim=-1)
def forward(self, dec_state, enc_out, mask=None):
# dec_state: [B, H_d], enc_out: [B, S, H_e2]
if self.lin is not None:
enc_proj = self.lin(enc_out) # [B,S,H_d]
else:
enc_proj = enc_out # [B,S,H_d]
scores = torch.bmm(enc_proj, dec_state.unsqueeze(-1)).squeeze(-1) # [B,S]
if mask is not None:
scores = scores.masked_fill(~mask, -1e9)
attn = self.softmax(scores) # [B,S]
ctx = torch.bmm(attn.unsqueeze(1), enc_out).squeeze(1) # [B,H_e2]
return ctx, attn
Uses dot-product scores and returns a weighted context vector plus attention weights.
Step 7: Decoder (GRU) + Attention Fusion head
At each step: embed prev token → update decoder state → compute attention → fuse and predict.
class Decoder(nn.Module):
def __init__(self, vocab_size, emb=128, hid_dec=256, hid_enc2=512):
super().__init__()
self.emb = nn.Embedding(vocab_size, emb, padding_idx=stoi[PAD])
self.gru = nn.GRU(emb, hid_dec, batch_first=True)
self.attn = LuongAttention(hid_enc2, hid_dec)
self.fuse = nn.Linear(hid_dec + hid_enc2, hid_dec)
self.out = nn.Linear(hid_dec, vocab_size)
def forward(self, y_inp, h0, enc_out, src_mask=None):
# y_inp: [B,T_in], h0: [1,B,H_d], enc_out: [B,S,H_e2]
e = self.emb(y_inp) # [B,T,E]
h = h0.unsqueeze(0) # [1,B,H]
B, T, _ = e.size()
logits = []
for t in range(T):
o, h = self.gru(e[:, t:t+1, :], h) # o: [B,1,H]
dec_state = o.squeeze(1) # [B,H]
ctx, _ = self.attn(dec_state, enc_out, mask=src_mask)
fused = torch.tanh(self.fuse(torch.cat([dec_state, ctx], dim=-1))) # [B,H]
logits.append(self.out(fused)) # [B,V]
return torch.stack(logits, dim=1) # [B,T,V]
Produces token-level logits by combining decoder state with the attention-derived context.
Step 8: Seq2Seq wrapper, loss, training loop
Teacher-forced training with padding ignored.
class Seq2Seq(nn.Module):
def __init__(self, enc, dec):
super().__init__()
self.enc, self.dec = enc, dec
def forward(self, x, y_inp, src_mask=None):
enc_out, h0 = self.enc(x)
# project h0 to decoder size if needed
if h0.size(-1) != self.dec.gru.hidden_size:
proj = nn.Linear(h0.size(-1), self.dec.gru.hidden_size).to(h0.device)
h0 = proj(h0)
return self.dec(y_inp, h0, enc_out, src_mask)
enc = Encoder(vocab_size, emb=128, hid=128).to(device) # 2H = 256
dec = Decoder(vocab_size, emb=128, hid_dec=256, hid_enc2=256).to(device)
model = Seq2Seq(enc, dec).to(device)
crit = nn.CrossEntropyLoss(ignore_index=stoi[PAD])
opt = torch.optim.Adam(model.parameters(), lr=2e-3)
def make_src_mask(x):
# True where tokens are valid (not PAD)
return (x != stoi[PAD])
EPOCHS = 20
for ep in range(1, EPOCHS+1):
model.train(); total = 0.0
for x,y in dl:
x,y = x.to(device), y.to(device)
y_inp = y[:, :-1]
y_tgt = y[:, 1:]
logits = model(x, y_inp, src_mask=make_src_mask(x)) # [B,T,V]
loss = crit(logits.reshape(-1, vocab_size), y_tgt.reshape(-1))
opt.zero_grad(); loss.backward(); opt.step()
total += loss.item()
if ep % 5 == 0:
print(f"epoch {ep:02d} | loss {total/len(dl):.3f}")
Trains the model to predict the next target token, ignoring pads.
Step 9: Greedy decoding for inference
Generate answers from new (passage, question) pairs.
def greedy_generate(passage, question, max_len=8):
model.eval()
src = encode(tokenize(f"{passage} {SEP} {question}"))
x = torch.tensor([src]).to(device)
enc_out, h0 = model.enc(x)
if h0.size(-1) != model.dec.gru.hidden_size:
proj = nn.Linear(h0.size(-1), model.dec.gru.hidden_size).to(h0.device)
h0 = proj(h0)
y = [stoi[SOS]]
h = h0.unsqueeze(0)
for _ in range(max_len):
inp = torch.tensor([[y[-1]]], device=device)
e = model.dec.emb(inp)
o, h = model.dec.gru(e, h)
dec_state = o.squeeze(1)
ctx, _ = model.dec.attn(dec_state, enc_out, mask=make_src_mask(x))
fused = torch.tanh(model.dec.fuse(torch.cat([dec_state, ctx], dim=-1)))
logit = model.dec.out(fused) # [B,V]
next_id = int(logit.argmax(-1))
if next_id == stoi[EOS]: break
y.append(next_id)
toks = [itos[i] for i in y[1:]]
return " ".join(toks)
# quick try (after training):
print(greedy_generate("password reset link expires in 24 hours .",
"how long before the link expires ?"))
Runs the encoder once, then decodes step-by-step with attention to produce a short answer.
Quick Reference: Full Code
# === Toy QA with Luong Attention (compact) ===
import re, random, torch, torch.nn as nn
from torch.utils.data import Dataset, DataLoader
random.seed(7); torch.manual_seed(7)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
PAD,SOS,EOS,UNK = "<pad>","<sos>","<eos>","<unk>"; SEP="<q>"
RAW=[("order 1234 status is processing . payment received .","what is the order status ?","processing"),
("password reset link expires in 24 hours .","how long before the link expires ?","24 hours"),
("refund is issued within 5 business days .","when is refund issued ?","5 business days"),
("delivery takes 3–5 days in metro manila .","how long is delivery ?","3–5 days"),
("support is available from 9 am to 6 pm .","what are support hours ?","9 am to 6 pm"),
("orders marked shipped cannot be cancelled .","can a shipped order be cancelled ?","no"),
("express shipping costs 150 php .","how much is express shipping ?","150 php"),
("standard shipping is free over 1000 php .","when is shipping free ?","over 1000 php"),
("warranty covers factory defects for 12 months .","how long is the warranty ?","12 months"),
("returns require original receipt .","what is required for returns ?","original receipt"),
("chat support response time is under 2 minutes .","what is chat response time ?","under 2 minutes"),
("opening hours are monday to saturday only .","which days are open ?","monday to saturday")]
pairs=[(f"{p} {SEP} {q}",a) for (p,q,a) in RAW]
def tok(s): return re.sub(r"\s+"," ",s.lower().strip()).split()
from collections import Counter
cnt=Counter(); [cnt.update(tok(x)); cnt.update(tok(y)) for x,y in pairs]
itos=[PAD,SOS,EOS,UNK]+sorted([w for w,c in cnt.items() if w not in {PAD,SOS,EOS,UNK}])
stoi={w:i for i,w in enumerate(itos)}; V=len(itos)
def enc(toks, add_eos=True):
ids=[stoi.get(t, stoi[UNK]) for t in toks]
return [stoi[SOS]]+ids+([stoi[EOS]] if add_eos else [])
def pad_batch(seqs,pad=stoi[PAD]):
m=max(len(s) for s in seqs); return torch.tensor([s+[pad]*(m-len(s)) for s in seqs])
class DS(Dataset):
def __init__(self,p): self.p=p
def __len__(self): return len(self.p)
def __getitem__(self,i):
x,y=self.p[i]; return torch.tensor(enc(tok(x))), torch.tensor(enc(tok(y)))
def collate(b): xs,ys=zip(*b); return pad_batch(xs), pad_batch(ys)
dl=DataLoader(DS(pairs), batch_size=4, shuffle=True, collate_fn=collate)
def src_mask(x): return (x!=stoi[PAD])
class Enc(nn.Module):
def __init__(self,V,E=128,H=128):
super().__init__(); self.emb=nn.Embedding(V,E,padding_idx=stoi[PAD]); self.gru=nn.GRU(E,H,batch_first=True,bidirectional=True)
def forward(self,x):
e=self.emb(x); out,h=self.gru(e); h=torch.cat([h[-2],h[-1]],-1); return out,h
class Luong(nn.Module):
def __init__(self,He2,Hd):
super().__init__(); self.lin = nn.Linear(He2,Hd,False) if He2!=Hd else None; self.sm=nn.Softmax(-1)
def forward(self,ds,eo,mask=None):
ep=self.lin(eo) if self.lin else eo
sc=torch.bmm(ep, ds.unsqueeze(-1)).squeeze(-1)
if mask is not None: sc=sc.masked_fill(~mask, -1e9)
a=self.sm(sc); ctx=torch.bmm(a.unsqueeze(1), eo).squeeze(1); return ctx,a
class Dec(nn.Module):
def __init__(self,V,E=128,Hd=256,He2=256):
super().__init__(); self.emb=nn.Embedding(V,E,padding_idx=stoi[PAD]); self.gru=nn.GRU(E,Hd,batch_first=True)
self.attn=Luong(He2,Hd); self.fuse=nn.Linear(Hd+He2,Hd); self.out=nn.Linear(Hd,V)
def forward(self,y,h0,eo,mask=None):
e=self.emb(y); h=h0.unsqueeze(0); B,T,_=e.size(); L=[]
for t in range(T):
o,h=self.gru(e[:,t:t+1,:],h); ds=o.squeeze(1); ctx,_=self.attn(ds,eo,mask)
fu=torch.tanh(self.fuse(torch.cat([ds,ctx],-1))); L.append(self.out(fu))
return torch.stack(L,1)
class S2S(nn.Module):
def __init__(self,enc,dec): super().__init__(); self.enc, self.dec = enc, dec
def forward(self,x,y,mask=None):
eo,h0=self.enc(x)
if h0.size(-1)!=self.dec.gru.hidden_size:
self.proj=nn.Linear(h0.size(-1), self.dec.gru.hidden_size).to(h0.device); h0=self.proj(h0)
return self.dec(y,h0,eo,mask)
enc,dec=Enc(V).to(device),Dec(V,He2=256,Hd=256).to(device); model=S2S(enc,dec).to(device)
opt=torch.optim.Adam(model.parameters(),lr=2e-3); crit=nn.CrossEntropyLoss(ignore_index=stoi[PAD])
for ep in range(1,21):
model.train(); tot=0
for x,y in dl:
x,y=x.to(device),y.to(device); yi,yt=y[:,:-1],y[:,1:]
logit=model(x,yi,mask=src_mask(x)); loss=crit(logit.reshape(-1,V), yt.reshape(-1))
opt.zero_grad(); loss.backward(); opt.step(); tot+=loss.item()
if ep%5==0: print(ep, tot/len(dl))
def gen(p,q,max_len=8):
model.eval(); s=[enc(tok(f"{p} {SEP} {q}"))]; x=torch.tensor(s).to(device)
eo,h0=model.enc(x)
if h0.size(-1)!=model.dec.gru.hidden_size:
model.dec.proj=nn.Linear(h0.size(-1), model.dec.gru.hidden_size).to(h0.device); h0=model.dec.proj(h0)
y=[stoi[SOS]]; h=h0.unsqueeze(0)
for _ in range(max_len):
inp=torch.tensor([[y[-1]]],device=device); e=model.dec.emb(inp); o,h=model.dec.gru(e,h)
ds=o.squeeze(1); ctx,_=model.dec.attn(ds,eo,mask=src_mask(x))
fu=torch.tanh(model.dec.fuse(torch.cat([ds,ctx],-1))); nxt=int(model.dec.out(fu).argmax(-1))
if nxt==stoi[EOS]: break
y.append(nxt)
return " ".join([itos[i] for i in y[1:]])
print(gen("password reset link expires in 24 hours .","how long before the link expires ?"))
Real‑World Application — Customer Support Chatbot (Retrieval + Attention Generator)
We’ll simulate a FAQ knowledge base (KB), retrieve the most relevant paragraph with TF-IDF, then feed “retrieved passage
<q>user question” to our attention model to produce a concise answer.
Step 1: Mini KB and TF-IDF retriever
Use scikit-learn to rank paragraphs by cosine similarity to the question.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
KB = [
("Shipping times", "Delivery takes 3–5 days in Metro Manila and 5–7 days provincial."),
("Refund policy", "Refund is issued within 5 business days once approved."),
("Password reset", "Password reset links expire in 24 hours for security."),
("Express shipping", "Express shipping costs 150 PHP with same-day dispatch."),
("Free shipping", "Standard shipping is free for orders over 1000 PHP."),
("Support hours", "Support is available from 9 AM to 6 PM, Monday to Saturday."),
("Warranty", "Warranty covers factory defects for 12 months from purchase date."),
]
vect = TfidfVectorizer(lowercase=True, ngram_range=(1,2))
kb_texts = [p for _, p in KB]
X = vect.fit_transform(kb_texts)
def retrieve_passage(question, topk=1):
qv = vect.transform([question])
sims = cosine_similarity(qv, X).ravel()
idx = sims.argsort()[::-1][:topk]
return [kb_texts[i] for i in idx]
Creates a simple lexical retriever to select the most relevant KB passage(s).
Step 2: Auto-generate tiny training pairs from KB
Tight supervision improves domain answers.
TEMPLATES = [
("Password reset links expire in 24 hours for security.",
"how long before the link expires ?", "24 hours"),
("Delivery takes 3–5 days in Metro Manila and 5–7 days provincial.",
"how long is delivery in metro manila ?", "3–5 days"),
("Refund is issued within 5 business days once approved.",
"when is refund issued ?", "5 business days"),
("Standard shipping is free for orders over 1000 PHP.",
"when is shipping free ?", "over 1000 php"),
("Support is available from 9 AM to 6 PM, Monday to Saturday.",
"what are support hours ?", "9 am to 6 pm"),
("Express shipping costs 150 PHP with same-day dispatch.",
"how much is express shipping ?", "150 php"),
("Warranty covers factory defects for 12 months from purchase date.",
"how long is the warranty ?", "12 months"),
]
train_pairs = [(f"{p} {SEP} {q}", a) for (p,q,a) in TEMPLATES]
Creates labeled pairs aligned with the KB language.
Step 3: (Optional) Fine-tune the same attention model
You can re-use the toy model; here’s how you’d quickly fine-tune for domain language.
# Build a small domain dataset and retrain/fine-tune
all_pairs = pairs + train_pairs # union with toy pairs
ds2 = QADataset(all_pairs)
dl2 = DataLoader(ds2, batch_size=4, shuffle=True, collate_fn=collate)
for ep in range(1, 6): # small top-up fine-tune
model.train(); total = 0
for x,y in dl2:
x,y = x.to(device), y.to(device)
yi, yt = y[:, :-1], y[:, 1:]
logits = model(x, yi, src_mask=make_src_mask(x))
loss = crit(logits.reshape(-1, vocab_size), yt.reshape(-1))
opt.zero_grad(); loss.backward(); opt.step()
total += loss.item()
print(f"[KB-finetune] epoch {ep} | loss {total/len(dl2):.3f}")
Adapts the model to the KB style in a few quick epochs.
Step 4: End-to-end answer() with retrieval + generation
Compose the final pipeline.
src_lang, tgt_lang = "en", "fr"
max_len = 128
def preprocess(batch):
src = batch["translation"][src_lang]
tgt = batch["translation"][tgt_lang]
model_inputs = tok(src, max_length=max_len, truncation=True)
with tok.as_target_tokenizer():
labels = tok(tgt, max_length=max_len, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
train_tok = train_ds.map(preprocess, batched=True, remove_columns=train_ds.column_names)
test_tok = test_ds.map(preprocess, batched=True, remove_columns=test_ds.column_names)
Retrieves the most relevant KB snippet then uses the attention model to produce a short, targeted answer.
Step 5: Notes on productionizing
Add confidence (e.g., average max-softmax) and threshold-based fallbacks.
Log inputs/outputs for supervision at scale.
Consider beam search for slightly better decoding, and coverage loss to reduce repetition.
Replace the encoder–decoder with a Transformer (easier scaling), or plug into an LLM RAG stack once you move to Phase 4.
Quick Reference: Full Code
# === Customer Support Chatbot (retrieval + attention generator) ===
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
KB=[("Shipping times","Delivery takes 3–5 days in Metro Manila and 5–7 days provincial."),
("Refund policy","Refund is issued within 5 business days once approved."),
("Password reset","Password reset links expire in 24 hours for security."),
("Express shipping","Express shipping costs 150 PHP with same-day dispatch."),
("Free shipping","Standard shipping is free for orders over 1000 PHP."),
("Support hours","Support is available from 9 AM to 6 PM, Monday to Saturday."),
("Warranty","Warranty covers factory defects for 12 months from purchase date."), ]
kb_texts=[p for _,p in KB]
vect=TfidfVectorizer(lowercase=True, ngram_range=(1,2)); X=vect.fit_transform(kb_texts)
def retrieve_passage(question, topk=1):
qv=vect.transform([question]); sims=cosine_similarity(qv,X).ravel(); idx=sims.argsort()[::-1][:topk]
return [kb_texts[i] for i in idx]
def answer(user_question, max_len=8):
top_passage=retrieve_passage(user_question, topk=1)[0]
ans=greedy_generate(top_passage, user_question, max_len=max_len) # uses model from Section 3
if not ans.strip(): ans = top_passage.split(".")[0].strip()
return {"passage": top_passage, "answer": ans}
print(answer("How long before the reset link expires?"))
Strengths & Limitations
Strengths
- Selective focus: Improves accuracy on long inputs by aligning question tokens to relevant passage tokens.
- Interpretable weights: Attention matrices
- Modular & scalable: Easily extends from Luong/Bahdanau to Transformer MHA, and to cross-attention for QA.
Limitations
- Quadratic cost: Self- and cross-attention are
- Not guaranteed faithfulness: High attention weight doesn’t always mean causal reliance; treat heatmaps as heuristics.
- Data sensitivity: Short-answer QA requires clean supervision; noisy labels lead to vague or repetitive outputs.
Final Notes
You implemented a seq2seq with attention that learns to extract short answers from a passage given a question, then wrapped it with a retriever to form a practical customer support assistant.
You also learned the math of attention (Bahdanau, Luong, scaled dot-product, multi-head) and the practicalities of masking, teacher forcing, and decoding. This is a solid foundation for transitioning to Transformers and, later, Generative AI with RAG.
Next Steps for You:
- Upgrade to Transformers: Replace the GRU encoder–decoder with a Transformer encoder–decoder. Use
with positional encodings and causal masks.
- Evaluation & datasets: Train on a public QA dataset (e.g., SQuAD) and report Exact Match (EM) and F1. Add beam search and coverage loss; log alignment visualizations.
- Efficient attention: Explore Longformer/Performer/FlashAttention for longer KB passages.
- RAG & production: Add document chunking, top-k retrieval, prompt templates, and guardrails; consider handing off to an LLM for edge cases (Phase 4).
References
[1] D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” ICLR, 2015.
[2] M.-T. Luong, H. Pham, and C. D. Manning, “Effective Approaches to Attention-based Neural Machine Translation,” EMNLP, 2015.
[3] A. Vaswani et al., “Attention Is All You Need,” NeurIPS, 2017.
[4] J. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, “Attention-Based Models for Speech Recognition,” NeurIPS, 2015.
[5] Z. Lin, M. Feng, C. N. dos Santos, M. Yu, B. Xiang, B. Zhou, and Y. Bengio, “A Structured Self-Attentive Sentence Embedding,” ICLR, 2017.
[6] M. Seo, A. Kembhavi, A. Farhadi, and H. Hajishirzi, “Bidirectional Attention Flow for Machine Comprehension,” ICLR, 2017.
[7] A. See, P. J. Liu, and C. D. Manning, “Get To The Point: Summarization with Pointer-Generator Networks,” ACL, 2017.
[8] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+ Questions for Machine Comprehension of Text,” EMNLP, 2016.

Leave a comment